Portfolio

Guanli (Leo) Liu · Backend Systems · Data Infrastructure · Research Engineering
I build data and AI systems, then turn them into reproducible, measurable products.
Postdoctoral researcher and engineer at the University of Melbourne. This site is organized as a growing portfolio of case studies across database systems, benchmarking, and LLM-assisted data workflows.
Portfolio Tracks
Each track will continue to grow with technical write-ups, demo snapshots, and code references.
Featured Build Stories
Projects are presented as build stories: problem context, technical implementation, and measurable outcome.
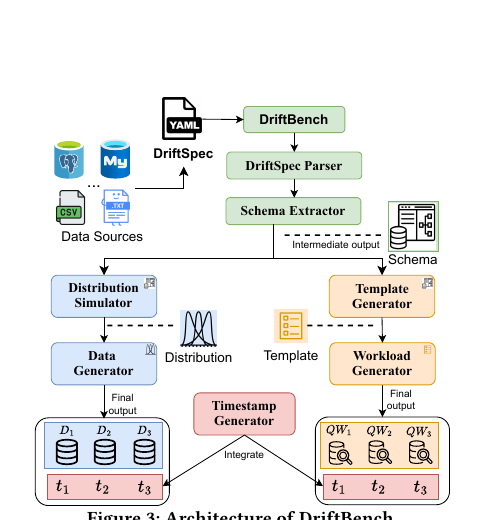
DriftBench
Built a full-stack drift-aware benchmarking system that helps database researchers generate, reuse, and reproduce evolving datasets and workloads with reproducible pipelines and release automation.
Stack: Python, CLI workflows, workload/data generators, CI/CD pipelines, benchmark automation.
AI-DB Extension Benchmark
Built a benchmark and evaluation workflow for AI-DB as a PostgreSQL extension, with recent integration of three core projects: HMAB, GRASP, and CoLSE, enabling unified testing and comparison under one extension-oriented runtime.
Stack: PostgreSQL extension workflows, Python automation, reproducible benchmark harnesses, performance analysis.
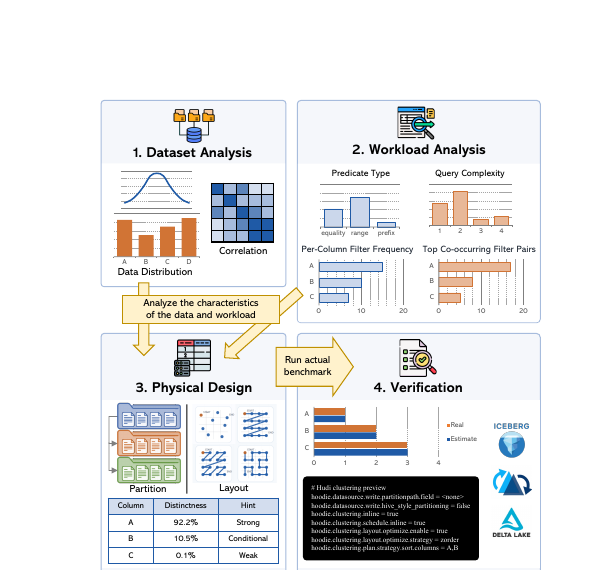
LayoutPilot / Layout Advisory
Designed an advisory backend for analytical data lake workloads, including workload ingestion, SQL parsing, and reusable decision logic for partitioning and intra-file layout choices.
Stack: Python, SQL parsing workflows, experiment harnesses, Dockerized service environment.
Metadata-Native Agent Workspace Infrastructure
Proposed and prototyped an infrastructure direction where metadata drives task-aware context routing, access control, and recoverable actions for agent workflows.
Public write-up and architecture notes will be published in an upcoming portfolio update.
LLM-Assisted Query Agents
Developed agents that translate natural language requests into executable database workflows through retrieval, query decomposition, and result-grounded evaluation.
Selected Publications
This section now reads from structured data and will be connected to the Scholar sync harness in the next workflow steps.
CoLSE: A Lightweight and Robust Hybrid Learned Model for Single-Table Cardinality Estimation using Joint CDF Published
Benchmarking RL-Enhanced Spatial Indices Against Traditional, Advanced, and Learned Counterparts Published
Efficient Cost Modeling of Space-filling Curves Published
Efficiently Learning Spatial Indices Published
Efficient Index Learning via Model Reuse and Fine-tuning Published
Effectively Learning Spatial Indices Published
Build Queue (Next Portfolio Drops)
- Blockchain Data Platform at nftDb: Kafka + Airflow ingestion and BigQuery analytics workflow case study.
- Baidu IM Backend: message protocol and deduplication reliability engineering breakdown.
- Evaluation Tooling: reusable experiment templates and CI-style benchmark validation pipeline.
Work Experience
2019-Present: Postdoctoral Research Fellow / PhD Researcher, The University of Melbourne (Melbourne, Australia).
Leading research and engineering projects on database benchmarking, indexing, data layout, and AI-driven query processing.
Designing system prototypes, supervising junior researchers, and co-supervising master's students on spatial indexing and database systems.
Building backend systems and reproducible evaluation pipelines for data and AI workloads.
2023-2024: Data Scientist / Data Infrastructure Engineer, nftDb (Melbourne, Australia).
Built blockchain ingestion pipelines, dbt and SQL analytics workflows, and BigQuery-based analysis.
Developed an internal RAG assistant for engineering knowledge retrieval.
2015-2017: Software Engineer, Baidu (China).
Worked on large-scale messaging systems and protocol design for internal communication platforms.
Improved message deduplication and database performance in production backend services.
Mentoring, Teaching, and Research Service
Mentoring and Supervision
- Co-supervising master's students on research projects in spatial indexing and database systems.
- Supervising junior researchers in reproducible benchmarking and AI-driven data systems projects.
Teaching
- COMP90018 - Android Application Development (The University of Melbourne): Tutor (Aug. 2019 - 2023), Responsible for tutorials, student support, and assessment marking.
- COMP90041 - Programming and Software Development (The University of Melbourne): Tutor (Aug. 2019 - 2023), Responsible for tutorials and assessment marking.
Research Service
- Conference Reviewer: SIGMOD 2026, ICDE 2027, VLDB 2027/2026/2025, KDD 2026/2025 (Excellent Reviewer).
- Journal Reviewer: TKDE, WWW, and Transactions on Spatial Algorithms and Systems (TSAS).